Read/Write Performance Observations
As I mentioned in my previous post, we have now moved more active mailboxes to the Sun Oracle 7000 Storage System. Active means, incoming mails, POP3/IMAP4 accesses etc.
Reads
First we will take a look at disk read latency. We can see that more than 50% are lower than 10ms.

A sanity check on one of the NFS-clients confirms this
We can see that the average service time over this 10 second sample is around 2ms. Usually I'm not interpreting the %b value too much, other than if it constantly is at 100%. Newer file-systems read/write in bursts, which makes it not a good problem indicator.
Next we will take a look at the read I/Os. We can see a moderate number of read I/Os per disk.
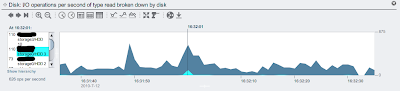
We can also see the bandwith usage for this operation. For comparison I've marked the same physical disk.

Writes
Writes are handled differently by the Oracle Storage 7000 systems, as syncronous writes are written to the SLOG/SSD devices. Asynchronous writes are collected into the ARC and then flushed to disk. You can see this as long bars in the latency graph.
A different view of this is the I/O per second graph for writes. The yellow area on the graph are the SLOG devices. You can see an almost straight line, whereas the blue area has some peaks.

The last graph shows the same as I/O bytes per second graph. Here we see about the same peaks.

Read/Write-Ratio
Looking at the read/write-ratio, shows us, that we have much more write I/Os than read I/Os.

Summary
Analytics helps us tremendously in monitoring how the system behaves during migration. This is especially important, with workloads, that can not be easily simulated.
As we already had ZFS experience, the patterns have not been too surprising. What comes to me as a surprise is the high write portion. On our FC-attached storage array, we see a ~ 50%/50% read/write ratio for the same workload using VxFS. While not being a problem at all, I will investigate the reason for this further.
Reads
First we will take a look at disk read latency. We can see that more than 50% are lower than 10ms.

A sanity check on one of the NFS-clients confirms this
r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device
73.6 36.5 494.4 317.7 0.0 0.3 0.1 2.4 1 22 filer:/filesystemb
39.8 31.7 322.2 445.4 0.0 0.1 0.4 1.8 1 12 filer:/filesystembWe can see that the average service time over this 10 second sample is around 2ms. Usually I'm not interpreting the %b value too much, other than if it constantly is at 100%. Newer file-systems read/write in bursts, which makes it not a good problem indicator.
Next we will take a look at the read I/Os. We can see a moderate number of read I/Os per disk.

We can also see the bandwith usage for this operation. For comparison I've marked the same physical disk.

Writes
Writes are handled differently by the Oracle Storage 7000 systems, as syncronous writes are written to the SLOG/SSD devices. Asynchronous writes are collected into the ARC and then flushed to disk. You can see this as long bars in the latency graph.

A different view of this is the I/O per second graph for writes. The yellow area on the graph are the SLOG devices. You can see an almost straight line, whereas the blue area has some peaks.

The last graph shows the same as I/O bytes per second graph. Here we see about the same peaks.

Read/Write-Ratio
Looking at the read/write-ratio, shows us, that we have much more write I/Os than read I/Os.

Summary
Analytics helps us tremendously in monitoring how the system behaves during migration. This is especially important, with workloads, that can not be easily simulated.
As we already had ZFS experience, the patterns have not been too surprising. What comes to me as a surprise is the high write portion. On our FC-attached storage array, we see a ~ 50%/50% read/write ratio for the same workload using VxFS. While not being a problem at all, I will investigate the reason for this further.

Comments