Heating up the Data Pipeline (Part 4)
In this last part of the "Heating up the Data Pipeline" blog series, we will go through some potentially useful NiFi dataflows.
Previous Parts: Part 1 Part 2 Part 3



Previous Parts: Part 1 Part 2 Part 3
Updating Splunk Lookup Files with SQL Query Data
The following simple workflow pulls data from a SQL Database using a JDBC connection. The ExecuteSQL processor returns data in Avro format. The results will be send through the ConvertRecord Processor to convert from Avro into CSV.
As Splunk does not allow to directly upload CSV files, we have to put the data into a Spooldir on the Splunk Server. In this case Splunk resides on the same server, so we can use the PutFile Processor.
We could also use the PutSFTP Processor for transferring the file to a remote server.
Finally we will assemble the proper POST request, and invoke the REST endpoint.

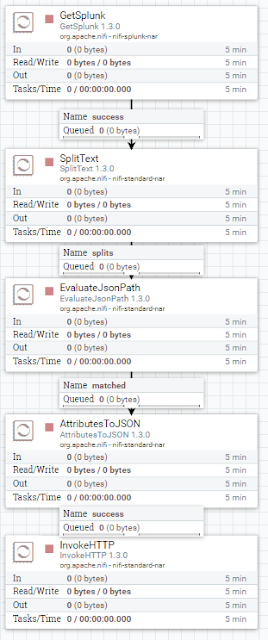
Splunk Event Copier
Sometimes you want to copy a subset of events from a production system to a test system in near-realtime. The following workflow uses the GetSplunk Processor to execute searches against a search head. The processor runs continuously and fetches new events based on _indextime and then emits one JSON document per event.
Using the EvaluateJSON document we will extract attributes, which we will again put together into a Splunk HEC compatible format.
Remember that you don't have to send data 1-to-1 to the target system. E.g. you could anonymize or mask the data on-the-fly.


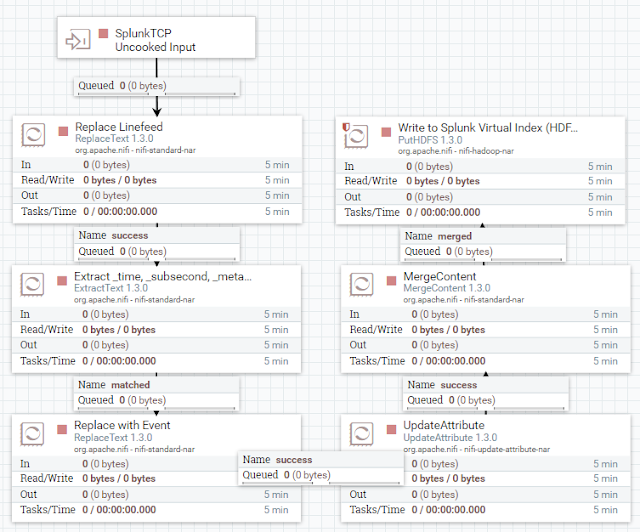
Sending Splunk Events to Files
There might be cases where events have to be writteninto files on a standard file system. Using extracted attributes and the NiFi Expression Language you can specify the directory structure where the files are put. Using the Merge processor, you can bundle multiple events into one file.
Remember that there is also a CompressContent Processor to compress the files if needed.


Time based path with NiFi Expression Language:
${sourcetype}_${filename}_${now():format('yyyyMMddHHmmss.SSS')}
Sending Splunk Events to HDFS Files
Maybe you want to send data to HDF Files. Instead of the PutFile Processor you would use the PutHDFS Processor.
With the right directory structure, you can easily access the data with Splunk Hadoop Analytics (formerly known as Hunk)!
Note: HDFS likes large files, so try to find the right relation between latency and file size, when playing with the MergeProcessor.
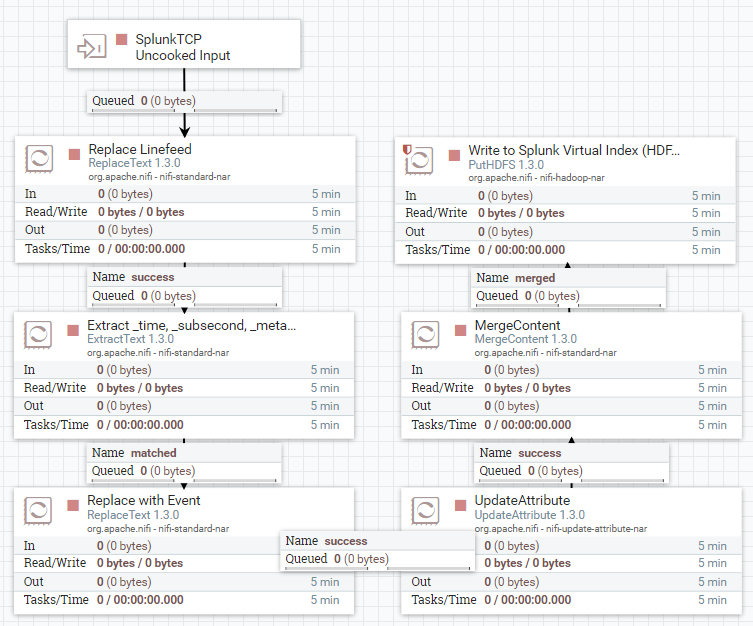
Sending Splunk Events to HDFS Parquet Files
Last but not least, Apache NiFi can also write data in HDFS Parquet Format. Also Parquet is supported by Splunk Hadoop Analytics, should you want to analyse this data.

Conclusion
I hope you have enjoyed this blog series about Splunk and Apache NiFi.
Apache NiFi is a powerful solution to fill the gaps when it comes to data pre-processing with Splunk.
We only scratched the surface here of what's possible with NiFi, and I'm very interested in use cases you will build. If you send them to me, I can post them on this blog.
Lastly, I would like to thank the very active NiFi community on the mailinglist for helping me building some of the workflows.

Comments