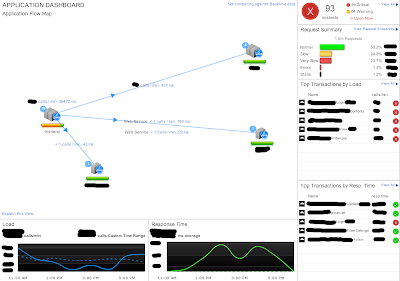
Who follows my blog, knows that I'm a Splunk addict, because I really like to know what my applications and systems are doing. Although Splunk is my favorite tool in my toolbox (and will be in the future... :-), there are some blind spots it can't see. We have struggled with some serious performance problems in one of our core applications during peak-hours. The application is Java-based, and usually performs well, when everything is ok. But during peak-hours, the response time gets worse and worse, having the side-effect of long major garbage collections. Not very user friendly, when there is a long stop-the-world. We were looking at the problem from the top (log analysis, monitoring) to the bottom (gc logs, jprofiler) never really finding the root cause of the problem. The fact that the problem did not occur all the time did not make it easier... As the situation got worse over time, and adding even more hardware was not really a solution, we were looking for some e...