Heating up the Data Pipeline (Part 3)
Welcome back to the "Heating up the Data Pipeline" blog series. In part 1 we talked about how to route data from Splunk to a 3rd party system. In part 2 walked through a simple data flow that passes data collected from Splunk Forwarders through Apache NiFi back to Splunk over the HTTP Event Collector.
In this part, we will look at a more complex use case, where we route events to an index, based on the sending host's classification. The classification will be looked up from a CSV file.
We will make use of Apache NiFi's new Record-Oriented data handling capabilities, which will look initially a bit more complicated, but once you grasp it, it will make further Use Cases easier and faster to build.


















In this part, we will look at a more complex use case, where we route events to an index, based on the sending host's classification. The classification will be looked up from a CSV file.
We will make use of Apache NiFi's new Record-Oriented data handling capabilities, which will look initially a bit more complicated, but once you grasp it, it will make further Use Cases easier and faster to build.
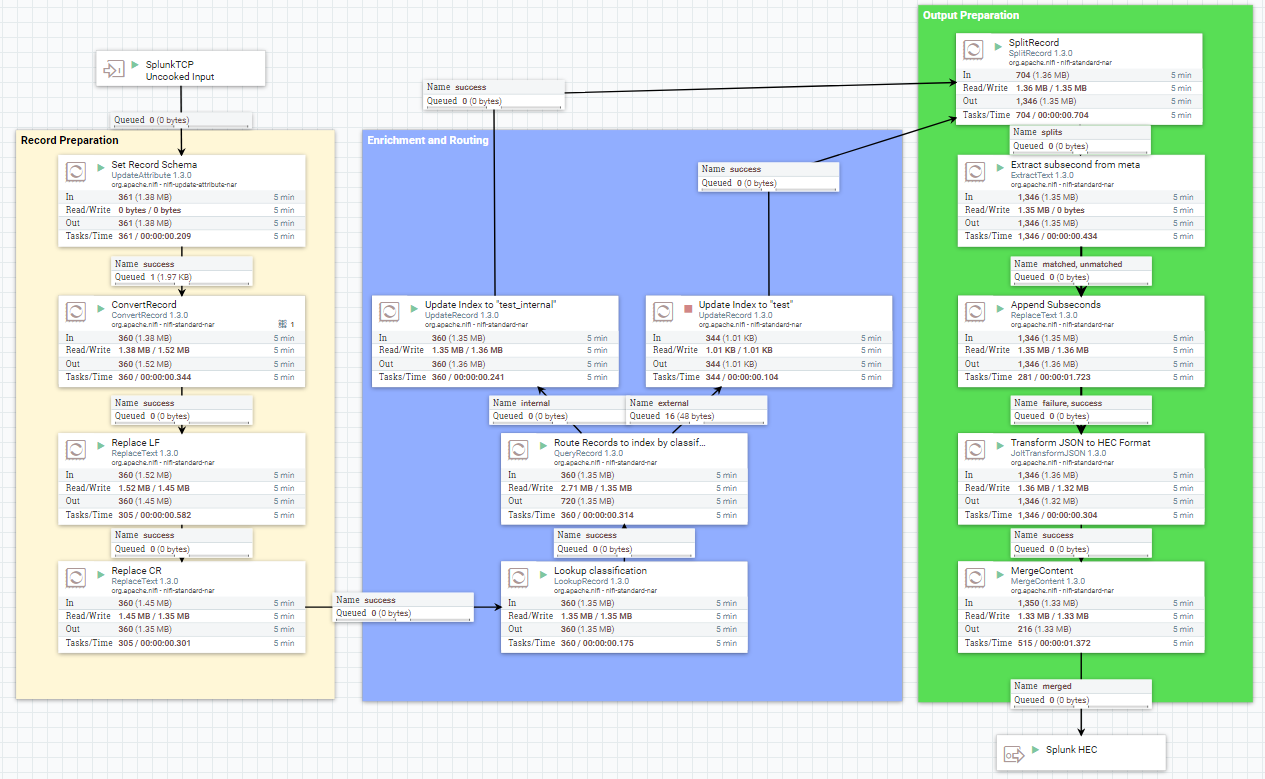
High-Level Dataflow
We will again start with our ListentTCP input, but this time we will send the data to another Processor Group. The Processor Group will again emit events suitable for Splunk HEC.

Note that we have increased the Max Batch Size from 1 to 1024 for higher throughput.

Let's look at the Data-flow in Detail. The flow consist of three parts.
The first step (yellow) is the preparation to process the event data not as raw events one event by one event, but as micro-batches pressed into a schema. After the preparation is done, the next step (blue) will enrich the records using a CSV lookup table. We will use the enrichment data to route the event.
Last but not least, step 3 (green) will prepare the data for Splunk HEC ingestion.
Record Preparation
Schema Attribute
Let's take a look at the first step in record preparation. The first step is to set an attribute called schema.name. The variable is a reference to an Avro Schema describing the record format.

The Avro schema itself is a JSON document which will describe the JSON document format, that we will use for our records.
{
"name": "SplunkHecEvent",
"namespace": "nifi.splunk.hec.event",
"type": "record",
"fields": [
{ "name": "time", "type": "string" },
{ "name": "host", "type": "string" },
{ "name": "sourcetype", "type": "string" },
{ "name": "source", "type": "string" },
{ "name": "index", "type": "string" },
{ "name": "meta", "type": "string" },
{ "name": "event", "type": "string" },
{ "name": "classification", "type": "string" }
]
}
Note, how this record contains most of the fields, Splunk HEC understands. There are two additional fields, meta and classification.
ConvertRecord Processor
Now comes the point, where we will convert our custom Splunk events into the records. This is done with the ConvertRecord Processor.


From the Properties tab, you can see that we have a Record Reader named GrokReader. This is a reference to a NiFi Controller Service providing a Grok Filter. We will use it's Regex capabilities to extract the JSON elements (fields). You can see part of the GrokExpression below.

As the Record Writer we use a Controler Service "JsonRecordSetWriter". We want the writer to print pretty JSON:

Are you wondering, how the Controller knows about the Schema? Remember that we set the schema.name attribute earlier. Setting the attribute within the flow, allows us to change the schema on the fly. Maybe you want to send data not only to Splunk HEC, but to another recipient, expecting a completely different format?
Below you see how the flowfiles look like. Instead of one event per flowfile we now have a multiple events within one flowfile. As you can remember, we told ListenTCP to set the Batch size to 1024. This means, that we can have up to 1024 events per flowfile.
[ {
"time" : "1499800765",
"host" : "LT-...",
"sourcetype" : "splunk_resource_usage",
"source" : "...",
"index" : "_introspection",
"meta" : "...",
"event" : "..."}}",
"classification" : null
},
...
{
"time" : "1499800765",
"host" : "LT-...",
"sourcetype" : "splunk_resource_usage",
"source" : "...",
"index" : "_introspection",
"meta" : "...",
"event" : "..."}}",
"classification" : null
}, } ]
ReplaceText Processors
Because the GrokReader can only handle single-line events. We will run our CR/LF Replacement Processors after the ConvertRecord Processor (See Part 2 of this blog series)
This step finishes our Record Preparation phase.
Enrichment and Routing
LookupRecord Processor
For our classification based routing we will need the help of the LookupRecord Processor. The processor uses a CSV file to do key/value lookups.

The properties tab reveals, that we will use again controller services for reading and writing data. The JsonTreeReader is just responsible to read the flowfile with the right schema. The JsonRecordSetWriter will do the opposite, it will write the output in the right schema format.
Below you can see, that the process will make use of the SimpleCsvFileLookupService. We will look at the service in a second.
You can see, that we have specified a key with the value "/host" and a ResultRecordPath with the value "/classification". The key specifies the path to the input value, while the ResultRecordPath specifies the path to where lookup return values will be written to. You can find more information about the syntax here.

Let's look at how the SimpleCsvFileLookupService is configured:

For the lookup service to work, a CSV File has to be specified. In this case we have a simple two column table with the columns host and classification. The CSV can have more columns, but you can only specify one key column and one value column.
How does a record look like after it has run through the Lookup Processor?
[ {
"time" : "1499802404",
"host" : "LT-...",
"sourcetype" : "WinEventLog:Security",
"source" : "WinEventLog:Security",
"index" : "default",
"meta" : "...",
"classification" : "internal"
} ]
If there is a match, the classification field will be updated from "null" to the value from the CSV file.
QueryRecord Processor
Based on the classification, we want to route events to different indexes. There are several options how to route events (e.g. RouteOnAttribute, RouteOnContent Processors), but for this showcase we will use the QueryRecord Processor.

The QueryRecord Processor is powered by Apache Calcite, which provides the functionality, to query Records using SQL. A detailed description can be found here.
From the properties page, you can see, that we have again a Record Reader and a Record Writer. We will not change the schema, so you can ignore this.
You'll also notice that we have two queries to find events with classification=external or classification=internal
The query is really simple:
SELECT * FROM FLOWFILE WHERE classification='external'
and
SELECT * FROM FLOWFILE WHERE classification='internal'
Events will be routed to different queues, depending on which query matches. Note in the picture on top, that the queues are named according to the property name.

UpdateRecord Processor
Based on the queue, the records will be routed to an UpdateRecord Processor. The index field will be replaced by a literal value test_internal.

Our events will look like this:
[ {
"time" : "1499802404",
"host" : "LT-...",
"sourcetype" : "WinEventLog:Security",
"source" : "WinEventLog:Security",
"index" : "default",
"meta" : "...",
"classification" : "test_internal"
} ]
Output Preparation
Our records are now ready to prepared for output.
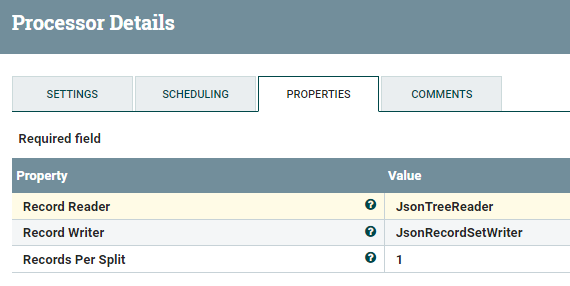
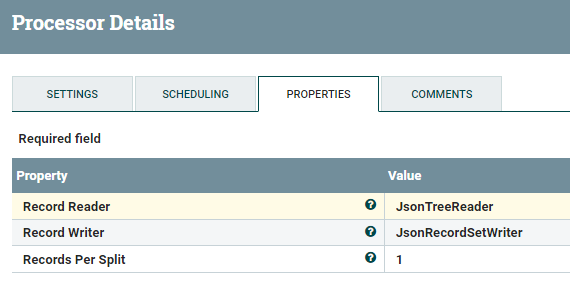
SplitRecord Processor
The SplitRecord Processor will split the records.

We just want one record per flowfile:
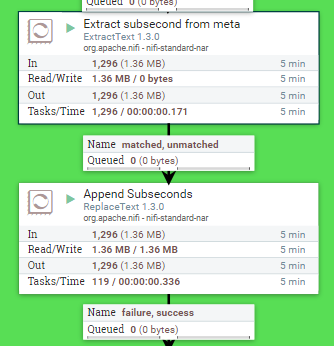
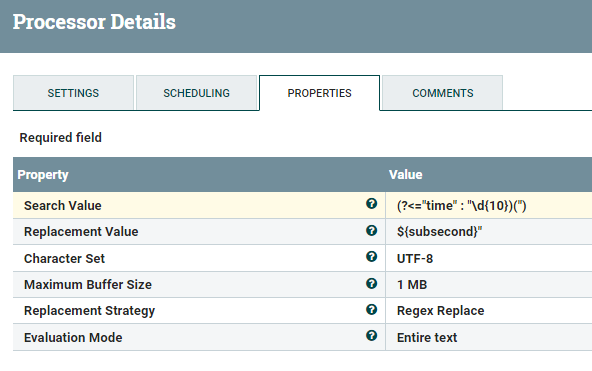
ExtractText / ReplaceText Processors
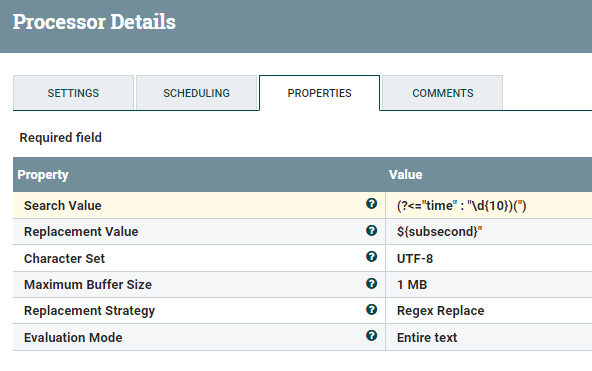
Like in part 2, we will extract subseconds from the metafield and append the subseconds to the time field.


JoltTransform Processor

The JSON document still contains two fields, which are not in the right location for a standard HEC request: The classification and the meta-field.
We could have thrown these fields away after our last Record Processor. I wanted to keep them because the content could still be valuable in Splunk. I don't want to change the raw event, so the best way to retain the data is to write the content into an indexed field.
For this, we need to move the two elements under an element called fields. the JoltTransform Processor is very handy for this.

The Jolt specification looks like this:
[
{
"operation": "shift",
"spec": {
"time": "time",
"host": "host",
"sourcetype": "sourcetype",
"source": "source",
"index": "index",
"event": "event",
"*": "fields.&(0)"
}
}
]
You can find more information about the Jolt DSL language here.
Our document now looks like this:
{
"time": "1499802404.358",
"host": "LT-...",
"sourcetype": "WinEventLog:Security",
"source": "WinEventLog:Security",
"index": "default",
"fields": {
"meta": "...",
"classification": "test_internal"
}
}
MergeContent Processor
The data is now in a format that Splunk HEC can understand. But sending data event-by-event, can produce heavy load on HEC. Fortunately, we can bundle events together with the MergeContentProcessor.

By setting Maximum Number of Entries to 1000 and Max Bin Age to 60s, we will lower the chance, that only single events will be sent over to Splunk HEC. Be aware, that a merge processor can cause latency, as the event data will be temporary cached.

Conclusion
Using Apache NiFi's record based approach, it is easy to enrich and route event data. Remember, that we only used a small subset of Processors and there are many more things that NiFi can do.
In Part 4, I will show you a few more Use Cases what you can do with NiFi. Or as Imperator Palpatine says: "Power, Unlimited power!!!!"

{kind=link}
Comments